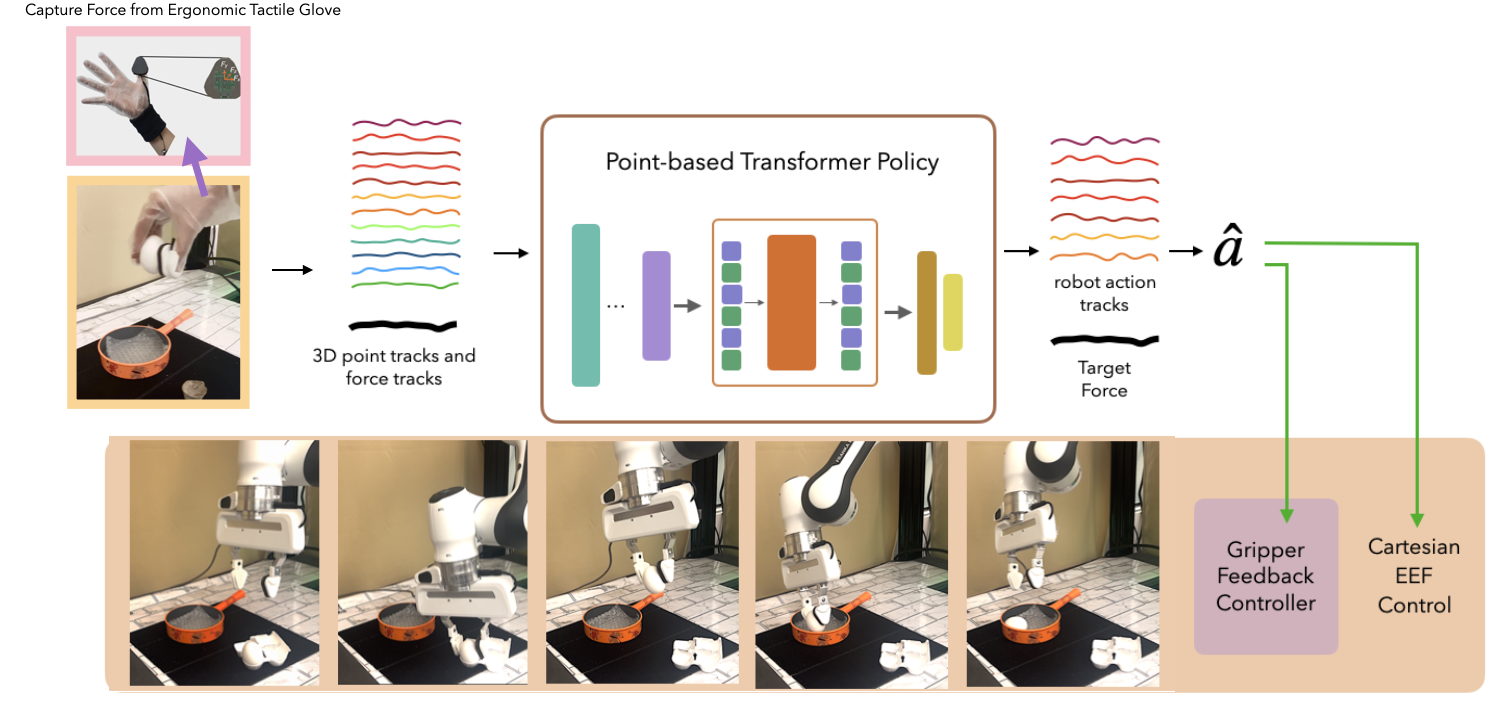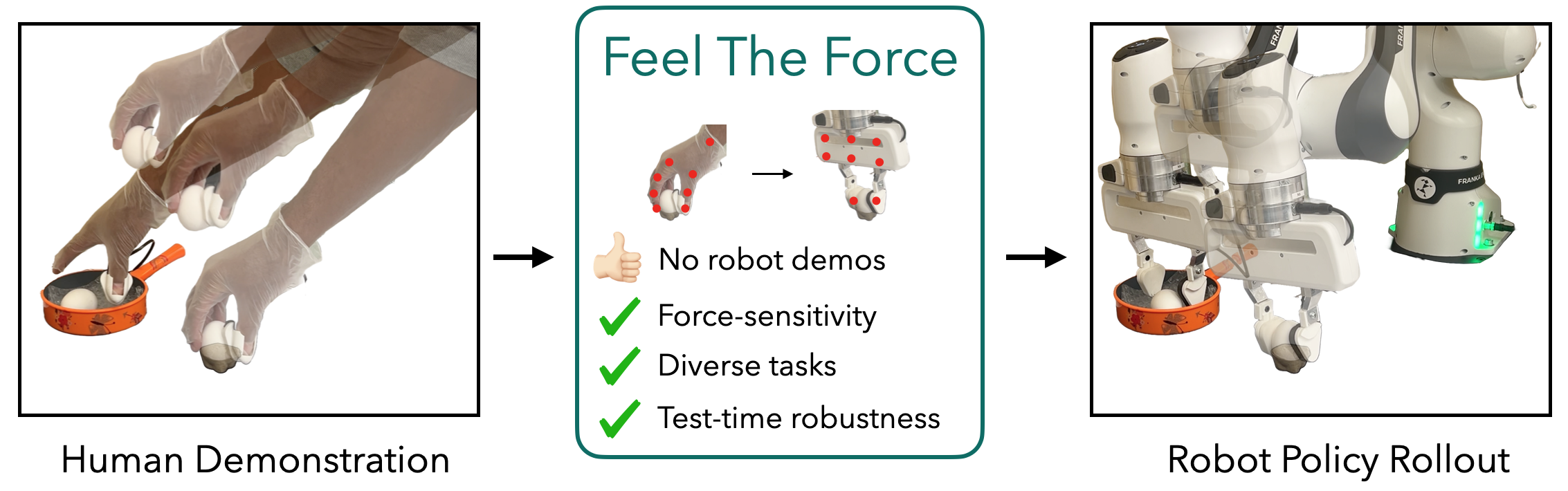
1. Tactile Data Collection
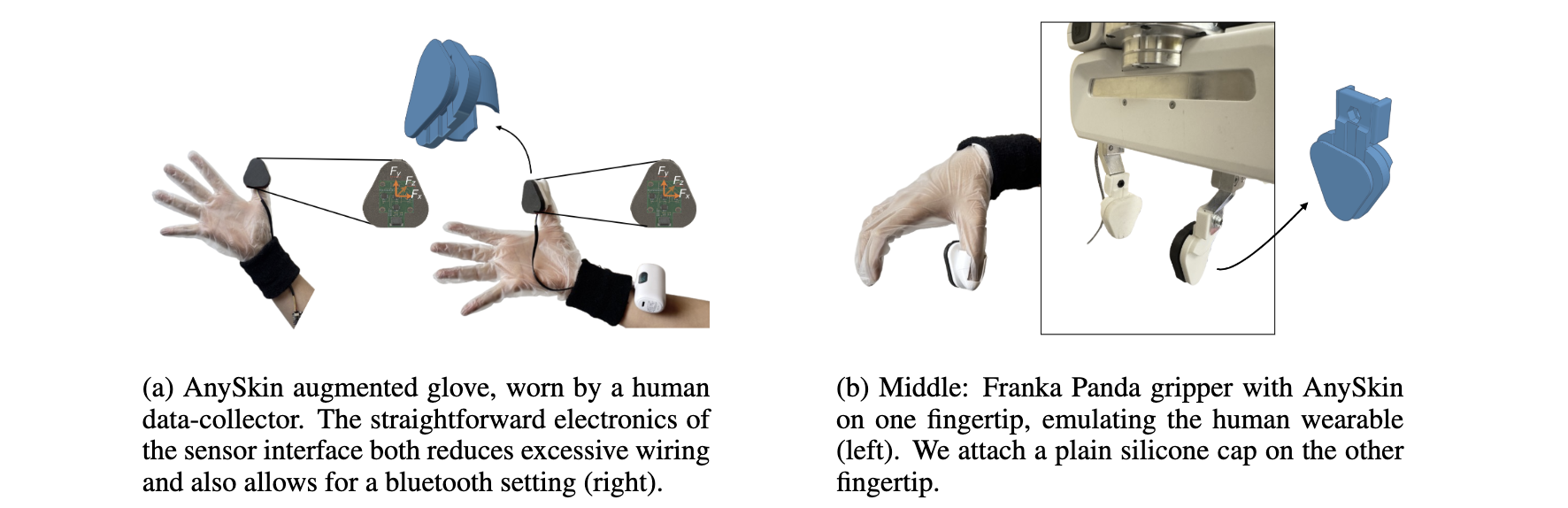
We design a custom, low-cost tactile glove inspired by AnySkin to capture 3D contact forces during natural human manipulation. The glove streams high-frequency force data, synchronized with stereo camera views capturing hand and object interactions. A tactile sensor is mounted on the robot's gripper to replicate the force sensing.
More details
The tactile glove places magnetometer-based sensors on the underside of the thumb to minimize occlusion. The sensor data is sampled at 200Hz and downsampled to align with 30Hz visual frames. The resulting force readings are used to supervise a policy trained entirely on human demonstrations, without requiring robot data.